네이버 부스트캠프 AI Tech/Deep Learning Basics
[부스트캠프 AI Tech] Recurrent Neural Network / Transformer
중앙백
2022. 2. 13. 20:42
Sequential Model
- Naive sequence model : p(xt|xt-1,xt-2,...)
- Autoregressive model : p(xt,|xt-1, ... , xt-n) Fix the past timespan
- Markov model(first-order autoregressive model) : p(x1,...,xT) = p(xT,|xT-1) p(xT-2|xT-3) ... p(x2|x1)
- Latent autoregressive model

출처 : 부스트캠프 AI Tech
Recurrent Neural Network

- Short-term dependencies : 멀리있는 정보일수록 영향력이 점차 희미해짐
Vanishing / exploding gradient
Long Short Term Memory (LSTM)

Gated Recurrent Unit

- No cell state, just hidden state
sequential model 문제를 다루기 힘들게 하는 요인
- Trimmed sequence : 손질
- Omitted sequence : 일부 생략
- Permuted sequence : 순서가 바뀜
Transformer

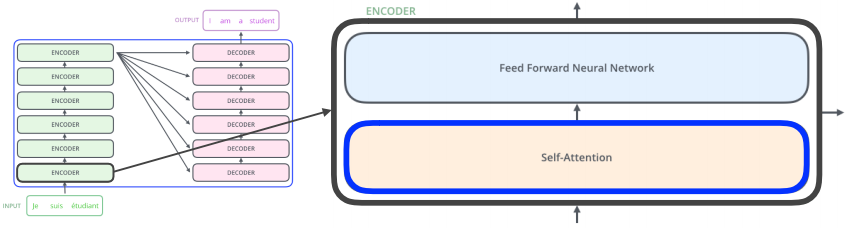
- self-attention in encoder and decoder
1. 각 단어를 embedding vector로 표현한다. + positional encoding
2. self-attention을 통해 embedding vector를 feature vector로 변환
⊙ Query, Key, Value
⊙ Attention weight : Softmax[(Query of one word) * (Key of each word) / (dimension of Key)]
⊙ Output = Sum(Attention weight * Value)
- Multi Head Attention
Head 별로 attention 계산 후에 weight를 곱해주어 원하는 사이즈로 조절
- Vision Transformer, DALL-E